课设
solidity
husky
旅游
.pdf预览
图书馆选座系统
CVE-2022-27925
OData
假设检验
远程工作
批量替换
知识计算
表示范围
命令链接按钮
飞书
天线
开发者搜索
python常见错误
新媒体
信号
微调
2024/4/12 13:33:36
LLM大模型开源案例集,需带有:数据集+模型微调+项目代码(三)
文章目录 1 ChatGLM-Med: 基于中文医学知识的ChatGLM模型微调1.1 数据集1.2 ChatGLM+P-tuning V2微调1.3 Llama + Alpaca的Lora微调版本2 LawGPT_zh:中文法律大模型(獬豸)2.1 数据集2.1.1 利用ChatGPT清洗CrimeKgAssitant数据集得到52k单轮问答:2.1.2 带有法律依据的情景问…

ChatGLM LoRA微调实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
国产开源类ChatGPT模型,ChatGLM-6b初步微调实验
ChatGLM-6b初步微调实验
chatglm-6b微调/推理, 样本为自动生成的整数/小数加减乘除运算, 可gpu/cpu chatglm-6b fine-tuning/inference, The sample is an automatically generated, integer/decimal of add, sub, mul and div operation, that can be gpu/cpu
项目地址
htt…
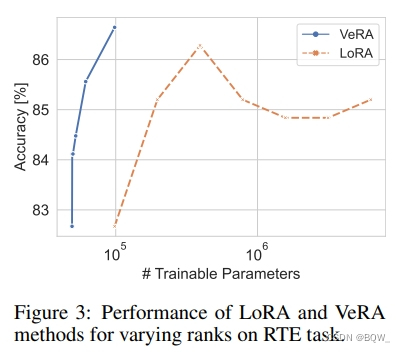
【自然语言处理】【大模型】VeRA:可调参数比LoRA小10倍的低秩微调方法
VeRA:可调参数比LoRA小10倍的低秩微调方法 《VeRA:Vector-based Random Matrix Adaptation》 论文地址:https://arxiv.org/pdf/2310.11454.pdf 相关博客 【自然语言处理】【大模型】VeRA:可调参数比LoRA小10倍的低秩微调方法 【自…
【ChatGLM2-6B】P-Tuning训练微调
机器配置
阿里云GPU规格ecs.gn6i-c4g1.xlargeNVIDIA T4显卡*1GPU显存16G*1
准备训练数据
进入/ChatGLM-6B/ptuningmkdir AdvertiseGencd AdvertiseGen上传 dev.json 和 train.json内容都是
{"content": "你是谁", "summary": "你好&…
自然语言处理从入门到应用——预训练模型总览:迁移学习与微调
分类目录:《自然语言处理从入门到应用》总目录 相关文章: 预训练模型总览:从宏观视角了解预训练模型 预训练模型总览:词嵌入的两大范式 预训练模型总览:两大任务类型 预训练模型总览:预训练模型的拓展 …
自然语言处理从入门到应用——预训练模型总览:预训练模型存在的问题
分类目录:《自然语言处理从入门到应用》总目录 相关文章: 预训练模型总览:从宏观视角了解预训练模型 预训练模型总览:词嵌入的两大范式 预训练模型总览:两大任务类型 预训练模型总览:预训练模型的拓展 …
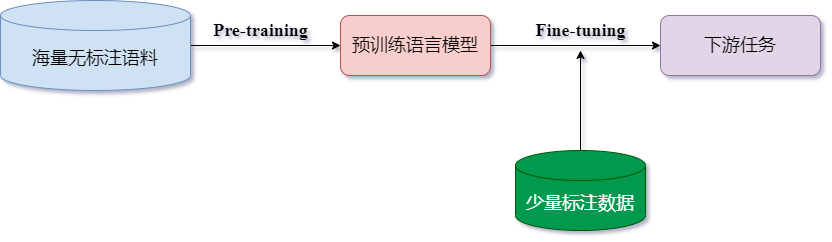
大语言模型微调和PEFT高效微调
目录标题 1 解释说明1.1 预训练阶段1.2 微调阶段2 几种微调算法2.1 在线微调2.2 高效微调2.2.1 RLHF2.2.2 LoRA2.2.3 Prefix Tuning2.2.4 Prompt Tuning2.2.5 P-Tuning v21 解释说明 预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一…
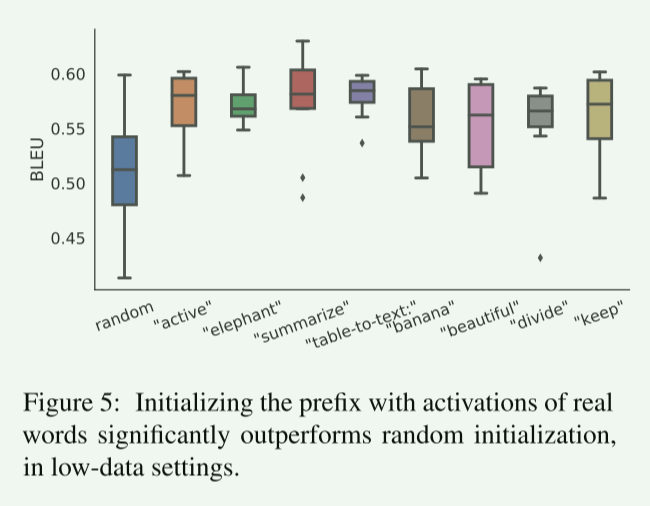
【论文精读ACL_2021】Prefix-Tuning: Optimizing Continuous Prompts for Generation
【论文精读ACL_2021】Prefix-Tuning: Optimizing Continuous Prompts for Generation 0、前言Abstract1 Introduction2 Related Work2.1 Fine-tuning for natural language generation.2.2 Lightweight fine-tuning2.3 Prompting.2.4 Controllable generation. 3 Problem State…
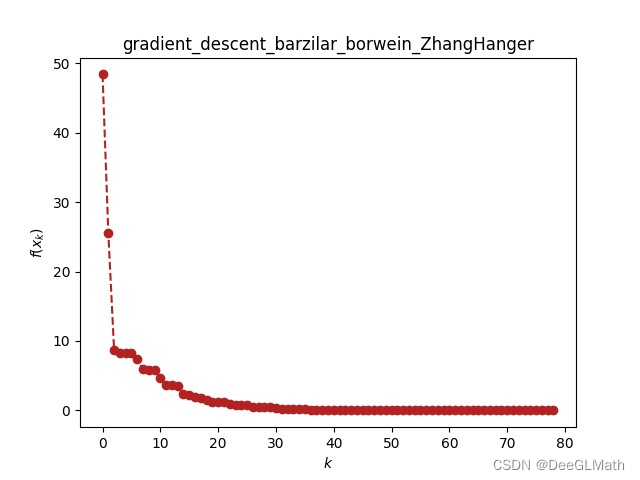
barzilar_borwein算法微调函数的优化收敛
import optimtool as oo
from optimtool.base import np, sp, pltpip install optimtool>2.4.2加载barzilar_borwein算法
import optimtool.unconstrain as ou
barzilar_borwein ou.gradient_descent.barzilar_borwein初始化输入数据 f ( x ) ∑ i 1 n / 2 c ( x 2 i −…

Prompt的技巧持续总结
Prompt 有很多网站已经收录了,比如:aimappro 有些直接抄上述网站的作业即可,不过也来看看, 有一些日常提问大概的咒语该怎么写。
1 三种微调下的提示写法
chatgpt时代的创新:LLM的应用模式比较 实际案例说明AI时代大…
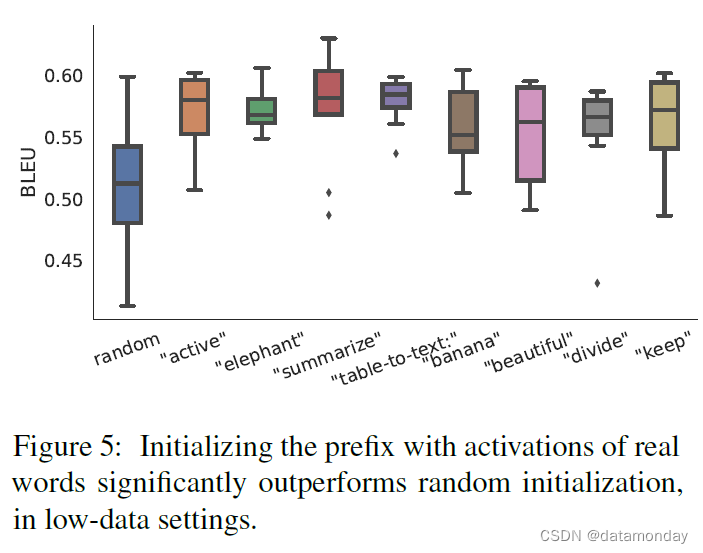
【LLM微调范式1】Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文标题:Prefix-Tuning: Optimizing Continuous Prompts for Generation 论文作者:Xiang Lisa Li, Percy Liang 论文原文:https://arxiv.org/abs/2101.00190 论文出处:ACL 2021 论文被引:1588(2023/10/14&…
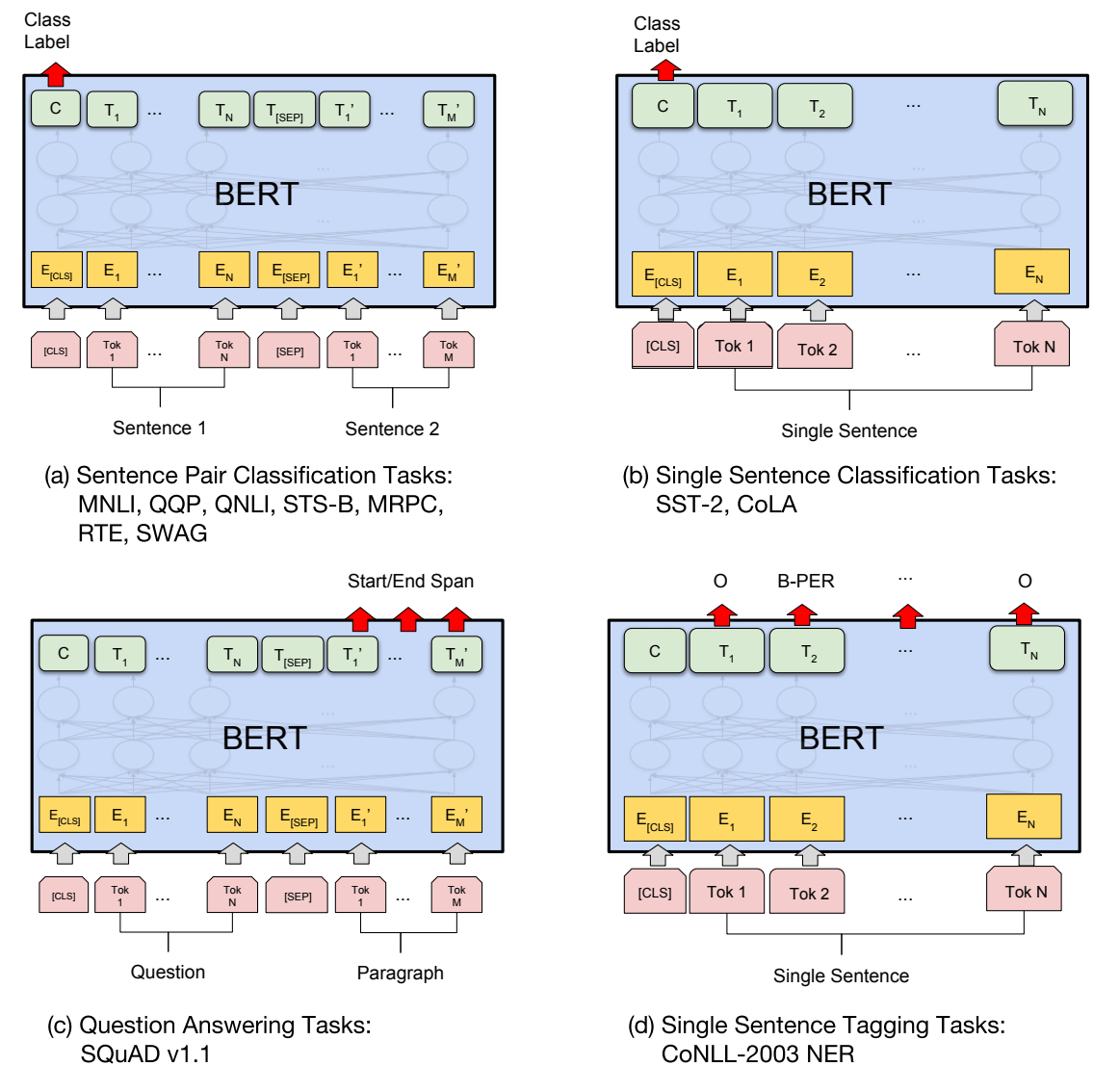
使用NNI对BERT模型进行粗剪枝、蒸馏与微调
前言
模型剪枝(Model Pruning)是一种用于减少神经网络模型尺寸和计算复杂度的技术。通过剪枝,可以去除模型中冗余的参数和连接,从而减小模型的存储需求和推理时间,同时保持模型的性能。模型剪枝的一般步骤:…
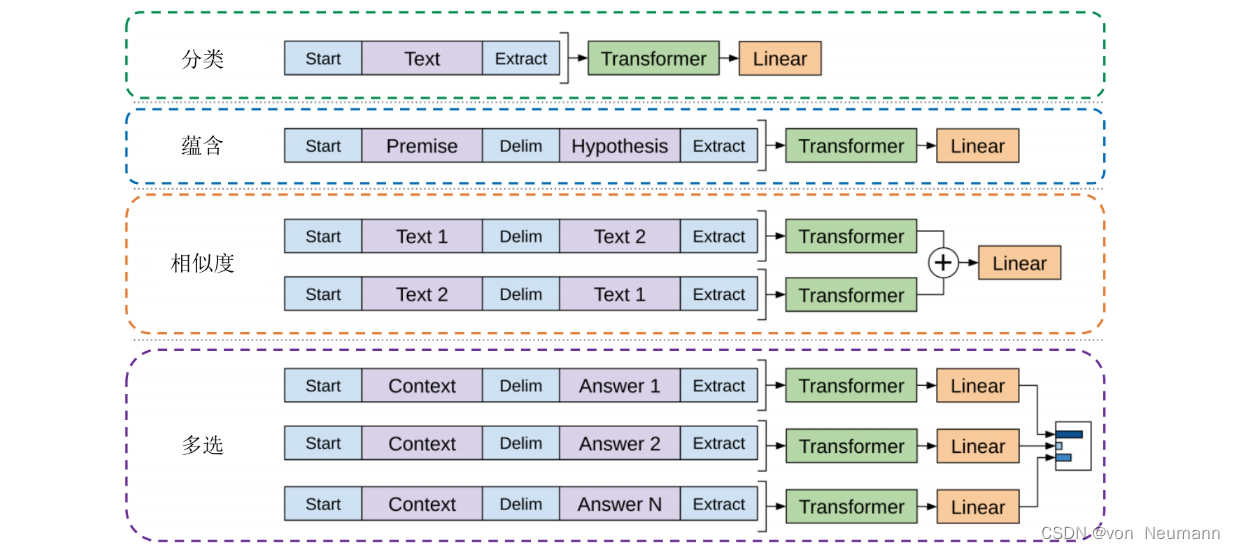
深入理解深度学习——GPT(Generative Pre-Trained Transformer):在不同任务中使用GPT
分类目录:《自然语言处理从入门到应用》总目录 相关文章: GPT(Generative Pre-Trained Transformer):基础知识 GPT(Generative Pre-Trained Transformer):在不同任务中使用GPT GP…

大模型下开源文档解析工具总结及技术思考
1 基于文档解析工具的方法
pdf解析工具
导图一览: PyPDF2提取txt: import PyPDF2
def extract_text_from_pdf(pdf_path):with open(pdf_path, rb) as file:pdf_reader PyPDF2.PdfFileReader(file)num_pages pdf_reader.numPagestext ""f…

Gemma谷歌(google)开源大模型微调实战(fintune gemma-2b)
Gemma-SFT
Gemma-SFT(谷歌, Google), gemma-2b/gemma-7b微调(transformers)/LORA(peft)/推理
项目地址
https://github.com/yongzhuo/gemma-sft全部weights要用fp32/tf32, 使用fp16微调十几或几十的步数后大概率lossnan;(即便layer-norm是fp32也不行, LLaMA就没有这个问题, …
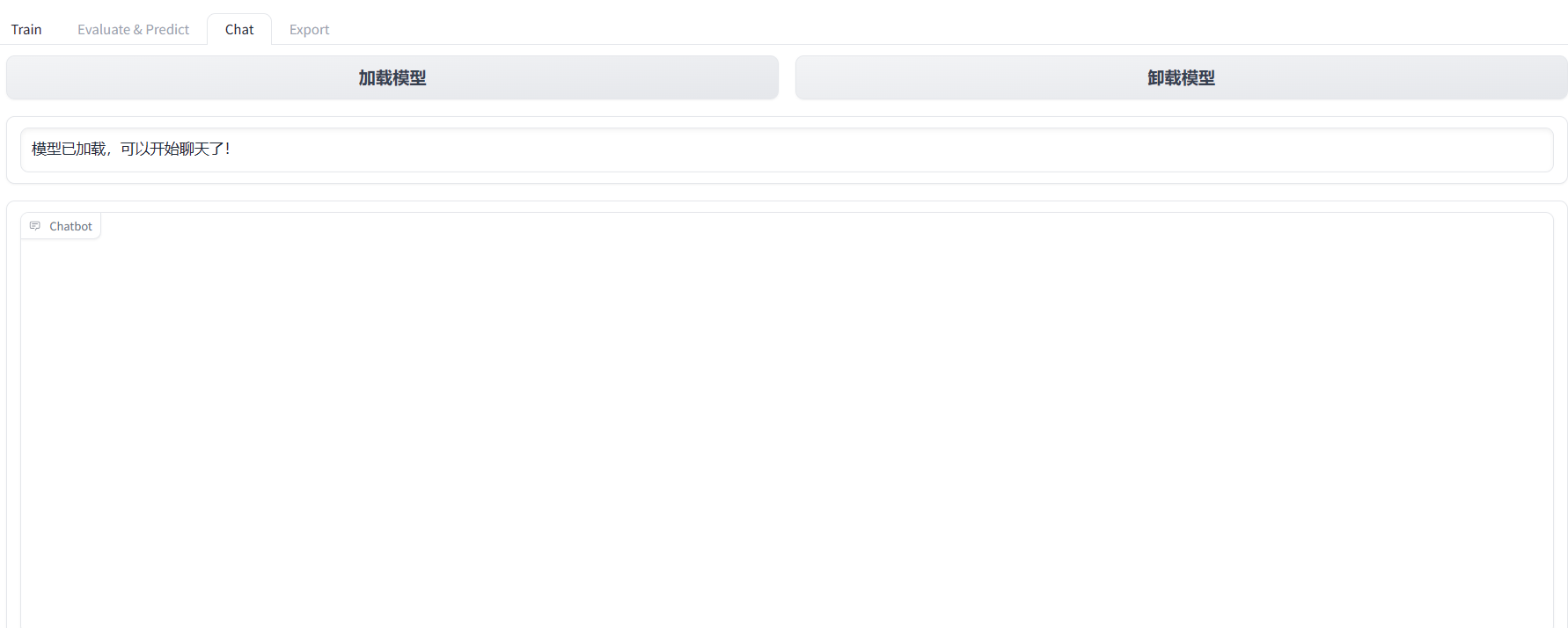
基于LLaMA-Factory的微调记录
文章目录 数据模型准备基于网页的简单微调基于网页的简单评测基于网页的简单聊天 LLaMA-Factory是一个非常好用的无代码微调框架,不管是在模型、微调方式还是参数设置上都提供了非常完备的支持,下面是对微调全过程的一个记录。 数据模型准备
微调时一般…
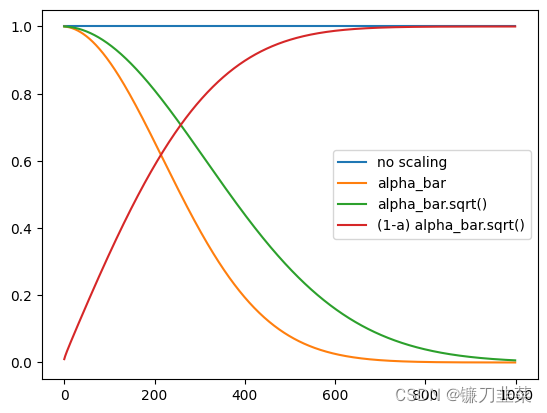
【扩散模型】理解扩散模型的微调(Fine-tuning)和引导(Guidance)
理解扩散模型的微调Fine-tuning和引导Guidance 1. 环境准备2. 加载预训练过的管线3. DDIM——更快的采样过程4. 微调5. 引导6. CLIP引导参考资料 微调(Fine-tuning)指的是在预先训练好的模型上进行进一步训练,以适应特定任务或领域的过程。这…
概念解析 | LoRA:低秩矩阵分解在神经网络微调中的作用
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:基于低秩矩阵分解的神经网络微调方法LoRA LoRA: Low-Rank Adaptation of Large Language Models LoRA由如下论文提出,详细信息请参见论文原文 https://arxiv.org/abs/2106.0968…
【微调大模型】如何利用开源大模型,微调出一个自己大模型
在人工智能的浪潮中,深度学习已经成为了最炙手可热的技术。其中,预训练大模型如Transformer、BERT等,凭借其强大的表示能力和泛化能力,在自然语言处理、计算机视觉等多个领域取得了显著的成功。然而,这些预训练大模型往往需要巨大的计算资源和时间成本,对于一般的研究者或…

一文读懂「Fine-tuning」微调
一、什么是微调?
1. 什么是微调?
微调是指在预训练模型(Pre-trained model)的基础上,针对特定任务或数据领域,对部分或全部模型参数进行进一步的训练和调整(Fine Tune)。预训练模型…

【极客技术】真假GPT-4?微调 Llama 2 以替代 GPT-3.5/4 已然可行!
近日小编在使用最新版GPT-4-Turbo模型(主要特点是支持128k输入和知识库截止日期是2023年4月)时,发现不同商家提供的模型回复出现不一致的情况,尤其是模型均承认自己知识库达到2023年4月,但当我们细问时,Fak…

从传统训练到预训练和微调的训练策略
目录 前言1 使用基础模型训练手段的传统训练策略1.1 随机初始化为模型提供初始点1.2 目标函数设定是优化性能的关键 2 BERT微调策略: 适应具体任务的精妙调整2.1 利用不同的representation和分类器进行微调2.2 通过fine-tuning适应具体任务 3 T5预训练策略: 统一任务形式以提高…
大模型的实践应用10-大模型领域知识与参数高效微调(PEFT)技术的详解,并利用PEFT训练自己的大模型
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用10-大模型领域知识与参数高效微调(PEFT)技术的详解,并利用PEFT训练自己的大模型。大模型领域的参数高效微调技术(PEFT)是指通过对大规模神经网络模型进行高效率的参数微调,以提高模型性能和效率的一种方法。PEFT技术通…
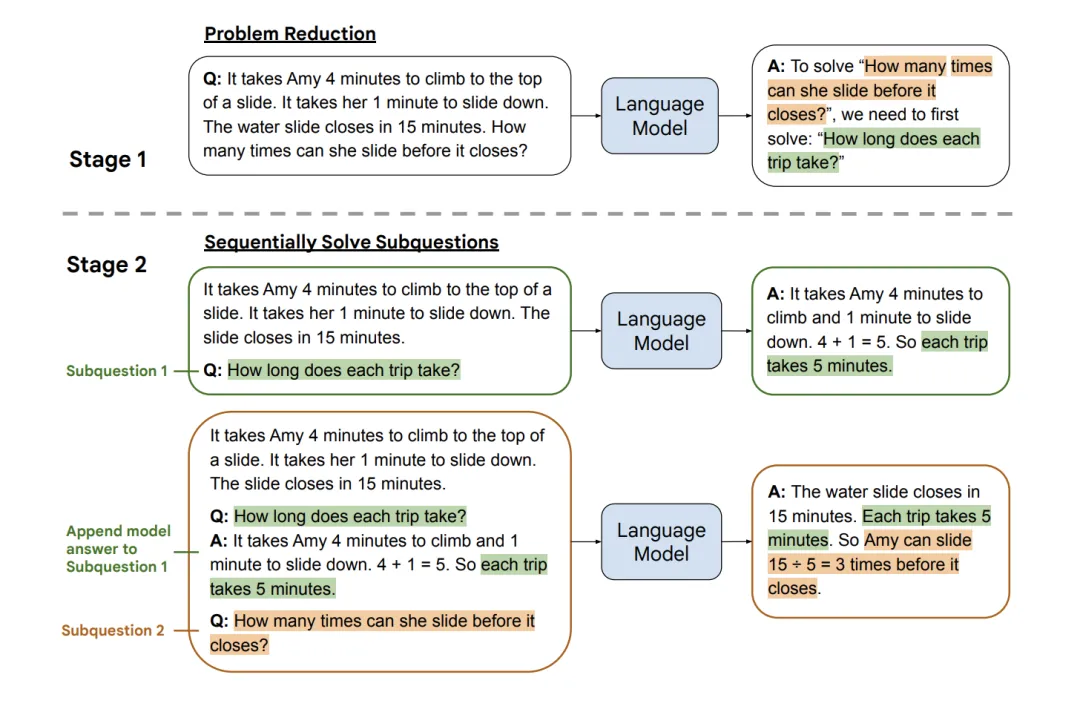
大语言模型LLM微调技术:Prompt Tuning
1 预训练语言模型概述
1.1 预训练语言模型的发展历程 截止23年3月底,语言模型发展走过了三个阶段:
第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer&#…

修改 ChatGLM2-6B 自我认知的 Lora 微调教程
修改 ChatGLM2-6B 自我认知的 Lora 微调教程 0. 背景1. 部署微调项目2. 数据集说明3. 模型监督微调(Lora)4. 模型效果测试5. 导出微调模型6. 调用导出的模型 0. 背景
现在开始学习微调,主要学习 Lora 微调。
这次尝试了修改 ChatGLM2-6B 自我认知,文章…
【ChatGLM2-6B】Docker下部署及微调
【ChatGLM2-6B】小白入门及Docker下部署 一、简介1、ChatGLM2是什么2、组成部分3、相关地址 二、基于Docker安装部署1、前提2、CentOS7安装NVIDIA显卡驱动1)查看服务器版本及显卡信息2)相关依赖安装3)显卡驱动安装 2、 CentOS7安装NVIDIA-Doc…
微调大型语言模型(LLM):应用案例示例
微调大型语言模型(LLM):应用案例示例
摘要: 本文讨论了大型语言模型(LLM)的微调,这是一种通过少量数据训练已经预训练好的模型以执行特定任务的过程。微调可以让LLM在翻译、文本分类、文本生成…
chatglm3-6b部署及微调
chatglm3-6b部署及微调
modelscope: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/filesgithub: https://github.com/THUDM/ChatGLM3镜像: ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4v100 16G现存 单卡
安装
软件依赖
pip install --upgrade pippip ins…

ChatGPT 学习笔记 | 什么是 Prompt-tuning?
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 Prompt-tuning is an efficient, low-cost way of adapting an AI foundation model to new downstream tasks without retraining the model and upd…

大语言模型的指令调优:综述
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 论文标题:Instruction Tuning for Large Language Models: A Survey
论文地址:https://arxiv.org/abs/2308.10792
指令调优是提升大语言模型(LLMs)性能…
『大模型笔记』大模型微调(Fine-Tuning)还有价值吗?
大模型微调(Fine-Tuning)还有价值吗? 文章目录 一. 大模型微调(Fine-Tuning)还有价值吗?二. 总结三. 参考文献对最近微调幻灭趋势的反应。一. 大模型微调(Fine-Tuning)还有价值吗? 我深入研究后发现,微调技术在众多场景下仍然极具价值。通常认为微调无益的人,往往是那些在…
EmoLLM-心理健康大模型
宣传一下自己最近参与的开源 https://github.com/aJupyter/EmoLLM
EmoLLM-心理健康大模型
EmoLLM 探索本项目的文档 查看Demo 报告Bug 提出新特性 EmoLLM 是一个能够支持 理解用户-支持用户-帮助用户 心理健康辅导链路的心理健康大模型,由 InternLM2 指令微…
自然语言处理:大语言模型入门介绍
自然语言处理:大语言模型入门介绍 语言模型的历史演进大语言模型基础知识预训练Pre-traning微调Fine-Tuning指令微调Instruction Tuning对齐微调Alignment Tuning 提示Prompt上下文学习In-context Learning思维链Chain-of-thought提示开发(调用ChatGPT的…

精细微调技术在大型预训练模型优化中的应用
目录 前言1 Delta微调简介2 参数微调的有效性2.1 通用知识的激发2.2 高效的优化手段3 Delta微调的类别3.1 增量式微调3.2 指定式微调3.3 重参数化方法 4 统一不同微调方法4.1 整合多种微调方法4.2 动态调整微调策略4.3 超参数搜索和优化 结语 前言
随着大型预训练模型在自然语…

【LLMs】从大语言模型到表征再到知识图谱
从大语言模型到表征再到知识图谱 InstructGLMLLM如何学习拓扑?构建InstructGLM泛化InstructGLM补充参考资料 2023年8月14日,张永峰等人的论文《Natural Language is All a Graph Needs》登上arXiv街头,轰动一时!本论文概述了一个名…
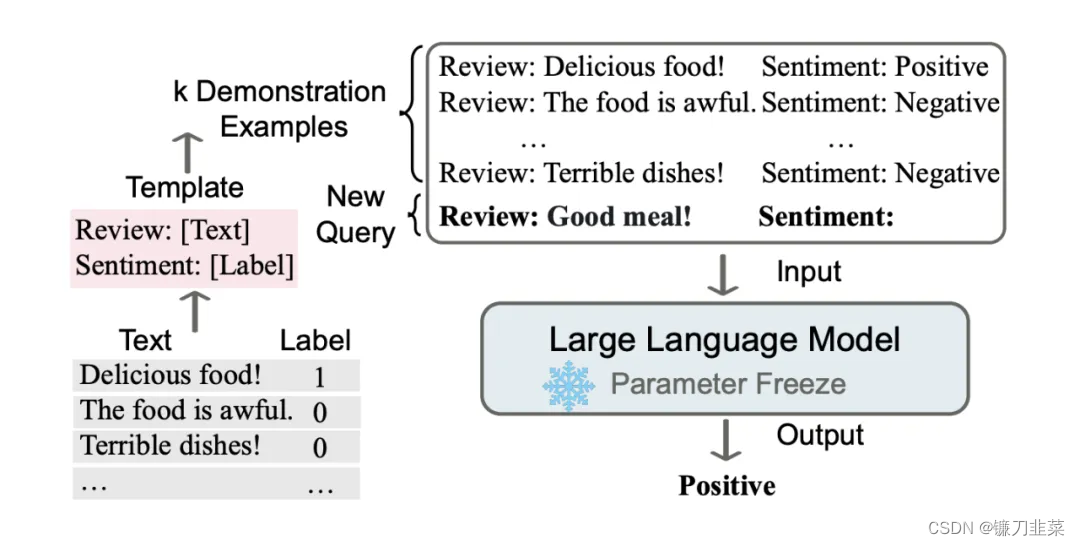
【大语言模型】5分钟了解预训练、微调和上下文学习
5分钟了解预训练、微调和上下文学习 什么是预训练?什么是微调?什么是上下文学习?相关资料 近年来大语言模型在自然语言理解和生成方面、多模态学习等方面取得了显著进展。这些模型通过
预训练、
微调和
上下文学习的组合来学习。本文将快速…
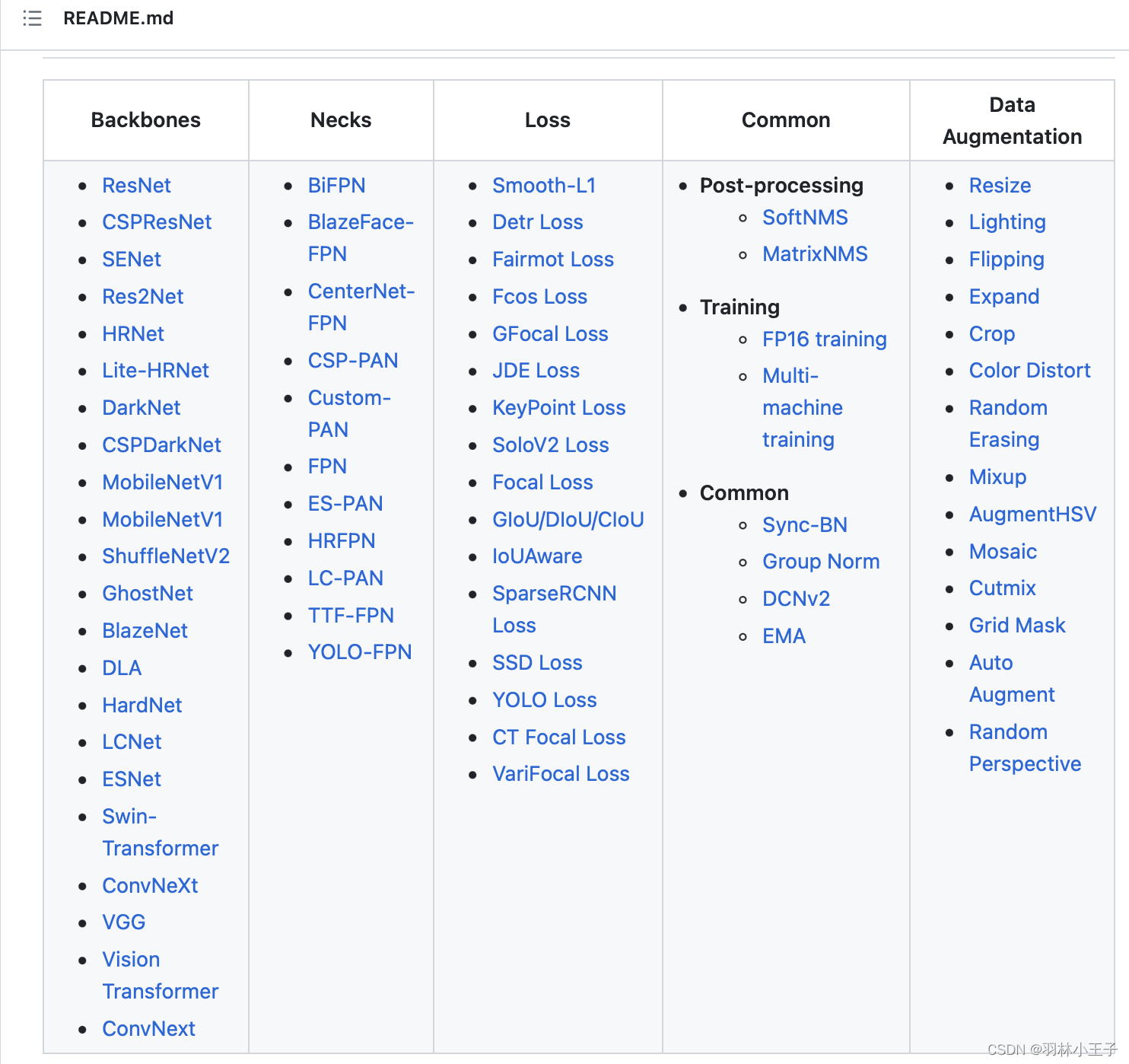
如何使用配置文件参数 - 实现预训练模型训练
如何使用配置文件参数 - 实现预训练模型训练 引言为什么使用配置文件来预训练模型呢 配置文件结构举例实现通过配置文件训练模型如何微调配置文件训练出优秀的模型呢数据集特征模型架构先前研究和经验超参数调优迭代实验和评估 引言
预训练模型在各个领域的应用取得了显著的成…
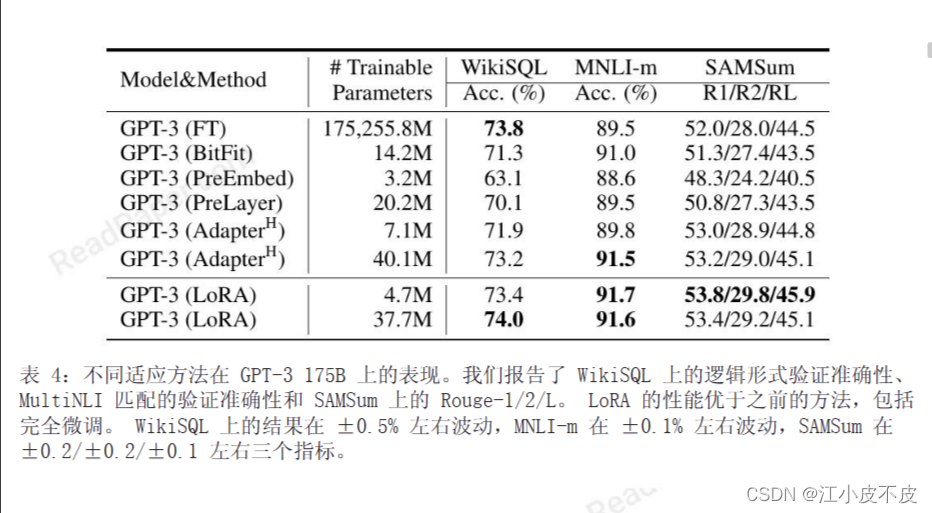
LORA概述: 大语言模型的低阶适应
LORA概述: 大语言模型的低阶适应 LORA: 大语言模型的低阶适应前言摘要论文十问实验RoBERTaDeBERTaGPT-2GPT-3 结论代码调用 LORA: 大语言模型的低阶适应
前言 LoRA的核心思想在于优化预训练语言模型的微调过程,通过有效地处理权重矩阵的变化(即梯度更新…
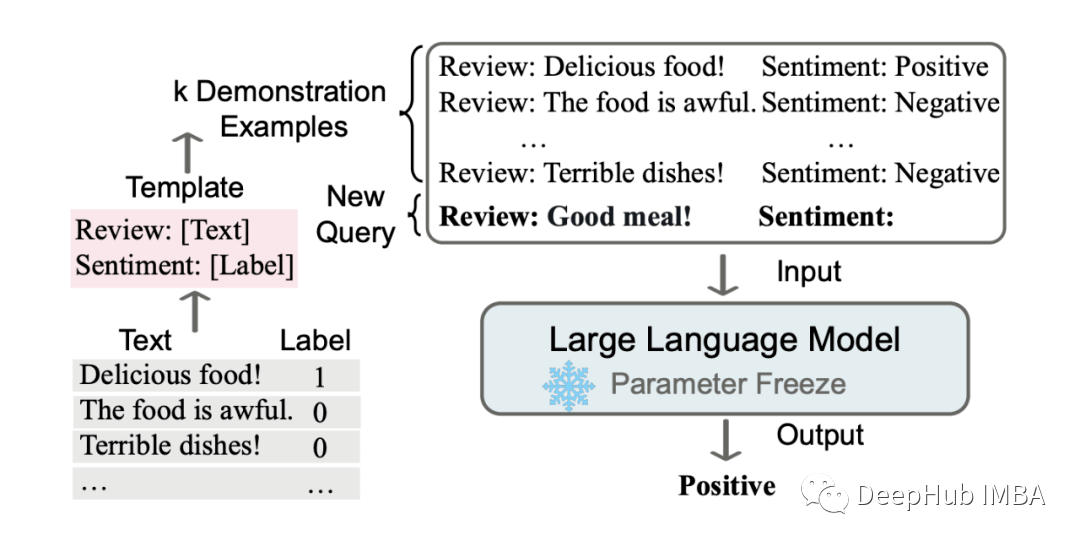
预训练、微调和上下文学习
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。 预训练
预训练(Pre-training&…
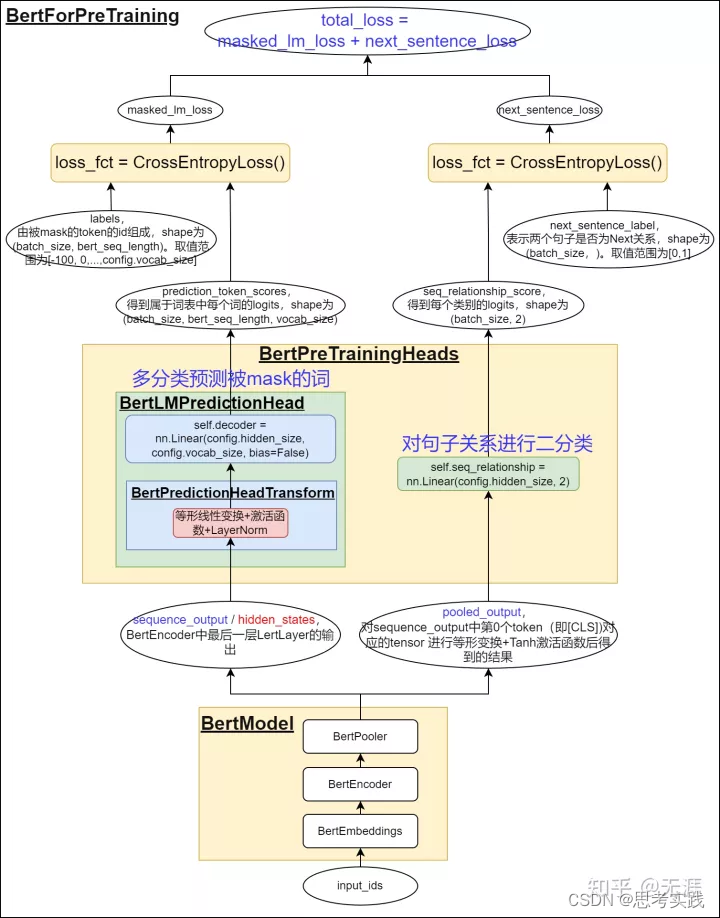
【LLM】预训练||两句话明白儿的底层原理
预训练鼻祖阶段:目前认为是Bert时期
从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的&#…
概念解析 | LoRA:低秩矩阵分解在神经网络微调中的魔力
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:基于低秩矩阵分解的神经网络微调方法LoRA LoRA:低秩矩阵分解在神经网络微调中的魔力 Low-Rank Adaptation of Large Language Models LoRA由如下论文提出,详细信息请参见论文原…

什么是大模型微调?微调的分类、方法、和步骤
2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据…
LoRA低秩微调技术详解
在当今快节奏的技术环境中,大型AI模型正在推动不同领域的突破。 然而,根据特定任务或数据集定制这些模型可能是一项计算和资源密集型工作。 LoRA是一种突破性且高效的微调技术,它利用这些高级模型的强大功能来执行自定义任务和数据集…

高效微调大型预训练模型的Prompt Learning方法
目录 前言1 prompt learning简介2 prompt learning步骤2.1 选择模型2.2 选择模板(Template)2.3 Verbalizer的构建 3 Prompt Learning训练策略3.1 Prompting组织数据,优化参数3.2 增加Soft Prompts,冻结模型,优化Prompt…
中文版GPT3——CPM(2.6B)微调长短文本生成(对应小说歌词)
CPM CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B。关于预训练模型的大量实验表明,更大的模型参数和更多的预训练数据,通常能…